A Simple Guide for Migrating Data
One common task in software engineering is to migrate data, and it’s worth taking some time to think strategically about how to design a system to do it. Once you start building your product or operations around data, you’ll likely need to add more features. Better decisions earlier will reduce complexity later.
I’ve built a few data pipelines in the past. Scaling a system of your own design over a long time is a wonderful learning experience. Some structural flaws only appear on longer time scales as you can observe how painfully your system adapts to each new requirement.
One useful mental model I’ve grown to use is to decompose all data migration tasks into components that migrate from source, to archive, and finally to utility locations where the actionable data will go. It’s not a new idea, but it’s worth explaining with simple terminology.
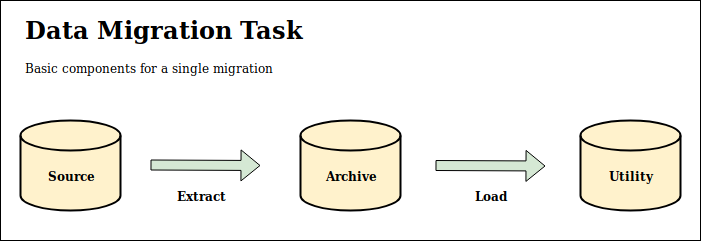
Source
The source storage is where the data originates and from where you’ll be extracting. This generally exists before you even start to consider this system. Some examples include:
- Your primary application-supporting DB (often Postgres/MySQL)
- Outside vendor that collects data on your behalf (Google Analytics, etc.)
- A third party data provider (Clearbit, etc.)
- Some public data source you may be scraping
Archive
The archive storage is an intermediate stage where you will dump your source data. The goal is to keep a complete, historical archive of your data. To be complete, it should include all attributes, timestamps, and metadata. Just dump everything. Your archive should also be structured to allow you to conveniently access information over any slice of time.
The archive storage is generally ignored for a quicker approach - why not just load the data from source to destination? As we’ll talk about later, adding an archive has wonderful benefits. It makes the system easier to maintain and grow.
When the time comes to choose the storage solution, the archive has pretty simple requirements. It needs to be able to house tons of data without worrying about hitting storage limits. It should be easy to dump and extract data in bulk and at high concurrency. It should also be cheap to store and easy to access from various programming environments to unlock opportunities for other teams to use it. There are many options - I’ve used AWS S3 as it meets all these requirements and lets you configure a retention policy to reduce costs.
Keep in mind that the right storage solution can vary by task. At MightySignal, we scraped the mobile app stores for rankings data across all countries, categories, etc. Even though we mostly used S3 for archive storage, we chose to use AWS Redshift for rankings. It met the basic requirements and let us more easily support historical querying because the rankings data model fit better with standard SQL tables.
Utility
This is the final destination, where your data will ultimately be moved. Your jobs will take data from the archive storage, transform it into the format you need, and then load it into the utility store. The goal is to do what’s best for the current business use case. Use whatever subset of data is relevant - the archive store serves as a durable backup.
Select a storage solution for the utility layer depending on how you plan to use it. Often the goal is to query across the entire dataset so a solution like Redshift, BigQuery, or Snowflake works here. Something like ElasticSearch would support a search product.
Connect them with Jobs
Now that the storage components are set, connecting them is easy to think about
- Write an extract job that moves data between your storage and archive locations
- Write a load job that takes data from the archive, transforms it into a useful format, and moves it to the utility location.
The jobs should be independent and only communicate through the historical layout of the archive. An extract job will gather source data at time X and file it into an appropriate place in the archive. And a load job will look for a period of time in the archive (which might include X), pull all the data, and load it into the destination.
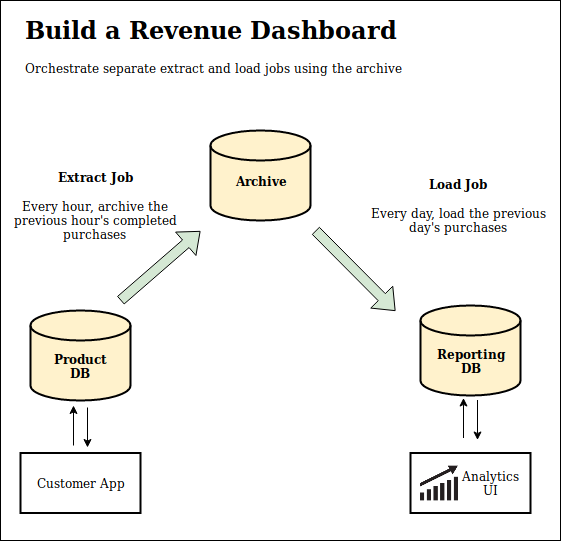
This independence is subtle but important. Decoupling the two jobs will let you rerun either one if it fails without touching the other. You can also modify their time ranges and frequencies independently - keep the extract job weekly but change the load job to monthly by just pulling an expanded time range from the archive.
A good scheduling tool will allow you to orchestrate those components. Cron works in the most basic case. I’ve used and recommend Airflow where possible. It can be as simple as cron but also allows you to write much more complex flows.
Why did I do all this?
The main reason is to make the system more flexible - the extra layer of abstraction provides options so it can grow to support more with fewer changes and sweeping rewrites. New uses for existing data can easily be implemented as another load job from the same archive to a different destination. Run it against older data sets from the archive to backfill it. Use this approach to build a v2 system without touching the code that powers v1. Sometimes data thought to be irrelevant turns out to be useful. The archive is complete and historical so you can go back and revisit.
The archive storage is critical for long term maintenance. It’s much easier to investigate what went wrong with the data loaded into the utility store if the archive holds the source. It also provides a great backup when mistakes happen, allowing complete rebuilds of any downstream destinations.
Lastly, each data store does fewer things and does them better. The archive storage doesn’t need to serve queries very quickly. The utility store doesn’t need to worry about holding all information, just whatever is accessed right now. Finding a data store that excels at everything is extremely rare - tools have to make tradeoffs. Fewer requirements let you make optimal choices at each layer.
Thanks to Marco, Maya, Pal, and Shubhro for helping revise drafts of this piece.